Dans le cadre de ma formation de trois jours « MongoDB – exploiter vos données efficacement », destinée à de futurs ingénieurs en informatique, je propose aux étudiants de réaliser les travaux dirigés dans le langage de programmation de leur choix.
De mon côté, j’en profite chaque année pour m’essayer à un nouveau langage ou pour me remettre à un langage que je n’ai pas pratiqué depuis longtemps. Cette année, je reviens à Java, que je n’ai plus pratiqué depuis 2020.
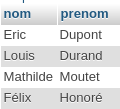
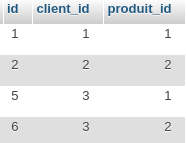
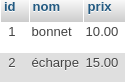
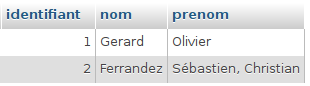
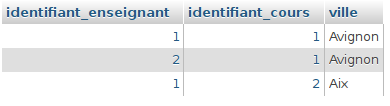
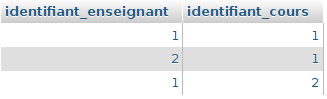
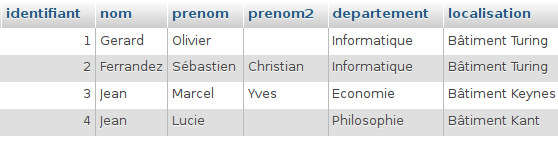
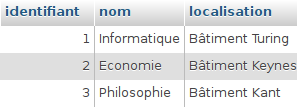
Nous avons d’abord exécuté toutes les requêtes de l’exercice sur la collection salles (PDF) à partir de l’interpréteur JavaScript du shell MongoDB accessible dans Compass, en nous connectant à des clusters créés sur Atlas. Ensuite, nous avons traduit ces requêtes dans le langage de programmation préféré de chaque étudiant.
Dépendances du projet
Le code repose sur un nombre très limité de dépendances afin de rester simple et facilement compréhensible par les étudiants. La première est le driver officiel MongoDB Java Sync, qui permet d’interagir avec la base de données en mode synchrone et d’exécuter les requêtes MongoDB depuis le code Java. J’ai également ajouté la bibliothèque dotenv-java, qui facilite la gestion des paramètres de configuration en permettant de charger les variables d’environnement à partir d’un fichier .env, pratique pour stocker les informations de connexion ou les identifiants sans les intégrer directement dans le code source. Enfin, la dépendance slf4j-simple fournit une implémentation minimale du framework de logging SLF4J, utilisée par le driver MongoDB pour afficher les logs.
<dependencies>
<dependency>
<groupid>org.mongodb</groupid>
<artifactid>mongodb-driver-sync</artifactid>
<version>5.2.0</version>
</dependency>
<dependency>
<groupid>io.github.cdimascio</groupid>
<artifactid>dotenv-java</artifactid>
<version>3.0.0</version>
</dependency>
<dependency>
<groupid>org.slf4j</groupid>
<artifactid>slf4j-simple</artifactid>
<version>2.0.13</version>
</dependency>
</dependencies>
Le fichier d’environnement
On y isole les credentials qui nous permettent de nous connecter à notre cluster fraîchement créé en ligne :
MONGO_USER=monutilisateur
MONGO_PASSWORD=monmotdepasse
MONGO_CLUSTER=url.de.mon.cluster.mongodb.net
MONGO_DB=mabasededonnees
MONGO_COLLECTION=salles
La classe principale
Notre main n’est pas bien compliqué : on y execute tous nos exercices contenus dans un repository dédié à notre collection salles. Ce repository est récupéré via l’appel à une fabrique dédiée.
package com.cesi.mongodb;
import com.mongodb.MongoException;
import com.mongodb.client.MongoClient;
import com.mongodb.client.MongoDatabase;
public class Main {
public static void main(String[] args) {
int exitCode = 0;
try (MongoClient client = MongoConnection.createClient()) {
MongoDatabase db = MongoConnection.getDatabase(client);
System.out.println("Connexion réussie à MongoDB !");
System.out.println("Database : " + db.getName());
runSallesExercices(db);
} catch (MongoException e) {
exitCode = 2;
System.err.println("Erreur MongoDB (connexion/requête) : " + e.getMessage());
e.printStackTrace(System.err);
} catch (RuntimeException e) {
exitCode = 1;
System.err.println("Erreur inattendue : " + e.getMessage());
e.printStackTrace(System.err);
} finally {
System.exit(exitCode);
}
}
private static void runSallesExercices(MongoDatabase db) {
RepositoryFactory factory = new RepositoryFactory(db);
SalleRepository repository = factory.salles();
runExercise(1, repository::exercice1);
runExercise(2, repository::exercice2);
runExercise(3, repository::exercice3);
runExercise(4, repository::exercice4);
runExercise(5, repository::exercice5);
runExercise(6, repository::exercice6);
runExercise(7, repository::exercice7);
runExercise(8, repository::exercice8);
runExercise(9, repository::exercice9);
runExercise(10, repository::exercice10);
}
private static void runExercise(int number, Runnable exercise) {
System.out.println("\n===== Exercice " + number + " =====");
exercise.run();
}
}
La fabrique de repositories
Elle ne contient qu’un seul type de repository à ce stade : celui dédié à la gestion de la collection salles, sur laquelle est basée l’exercice.
package com.cesi.mongodb;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import io.github.cdimascio.dotenv.Dotenv;
import org.bson.Document;
public final class RepositoryFactory {
private final MongoDatabase db;
private final Dotenv env;
public RepositoryFactory(MongoDatabase db) {
this(db, Dotenv.load());
}
public RepositoryFactory(MongoDatabase db, Dotenv env) {
this.db = db;
this.env = env;
}
public SalleRepository salles() {
String collectionName = getRequired("MONGO_COLLECTION", "salles");
MongoCollection<Document> collection = db.getCollection(collectionName);
return new SalleRepository(collection);
}
private String getRequired(String key, String defaultValue) {
String value = env.get(key);
if (value == null || value.isBlank()) {
return defaultValue;
}
return value;
}
}
Le repository dédié à la collection salles
Il contient la totalité de nos exercices, chacun isolé dans sa méthode de classe.
package com.cesi.mongodb;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.model.Sorts;
import com.mongodb.client.model.Updates;
import static com.mongodb.client.model.Filters.*;
import static com.mongodb.client.model.Projections.*;
import org.bson.BsonType;
import org.bson.Document;
import org.bson.conversions.Bson;
import java.time.Instant;
import java.util.Date;
import java.util.List;
import java.util.regex.Pattern;
public class SalleRepository {
private final MongoCollection<Document> collection;
public SalleRepository(MongoCollection<Document> collection) {
this.collection = collection;
}
public void exercice1() {
collection.find(eq("smac", true))
.projection(fields(include("_id", "nom")))
.forEach(doc -> System.out.println(doc.toJson()));
}
public void exercice2() {
collection.find(gt("capacite", 1000))
.projection(fields(excludeId(), include("nom")))
.forEach(doc -> System.out.println(doc.toJson()));
}
public void exercice3() {
collection.find(exists("adresse.numero", false))
.projection(fields(include("_id")))
.forEach(doc -> System.out.println(doc.toJson()));
}
public void exercice4() {
collection.find(size("avis", 1))
.projection(fields(include("_id", "nom")))
.forEach(doc -> System.out.println(doc.toJson()));
}
public void exercice5() {
collection.find(eq("styles", "blues"))
.projection(fields(excludeId(), include("styles")))
.forEach(doc -> System.out.println(doc.toJson()));
}
public void exercice6() {
collection.find(eq("styles.0", "blues"))
.projection(fields(excludeId(), include("styles")))
.forEach(doc -> System.out.println(doc.toJson()));
}
public void exercice7() {
Pattern regex = Pattern.compile("^84");
collection.find(and(regex("adresse.codePostal", regex), lt("capacite", 500)))
.projection(fields(excludeId(), include("adresse.ville")))
.forEach(doc -> System.out.println(doc.toJson()));
}
public void exercice8() {
collection.find(or(mod("_id", 2, 0), exists("avis", false)))
.projection(fields(include("_id")))
.forEach(doc -> System.out.println(doc.toJson()));
}
public void exercice9() {
collection.find(and(gte("avis.note", 8), lte("avis.note", 10)))
.projection(fields(excludeId(), include("nom")))
.forEach(doc -> System.out.println(doc.toJson()));
}
public void exercice10() {
Date after = Date.from(Instant.parse("2025-11-15T00:00:00Z"));
collection.find(gt("avis.date", after))
.projection(fields(excludeId(), include("nom")))
.forEach(doc -> System.out.println(doc.toJson()));
}
}
Pour exécuter tout ça, il ne reste plus qu’à compiler avec Maven avant. On met les logs MongoDB en mode warn pour éviter la pollution due au mode par défaut, INFO…
mvn compile
mvn exec:java -Dexec.mainClass="com.cesi.mongodb.Main" \
-Dorg.slf4j.simpleLogger.defaultLogLevel=info \
-Dorg.slf4j.simpleLogger.log.org.mongodb.driver=warn \
-Dorg.slf4j.simpleLogger.log.com.mongodb=warn