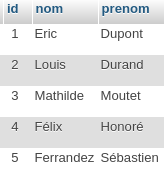
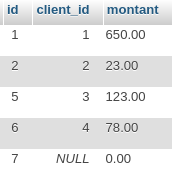
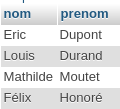
Le mot clé SQL EXISTS est ce que l’on appelle un prédicat, il évalue une (sous-)requête et dit si elle contient (true) ou non (false) des tuples. Pour travailler avec, nous allons utiliser deux tables au schéma simplissime, clients et commandes, dont voici les extensions, c’est à dire l’ensemble des tuples qu’elles contiennent.
Pour trouver les noms et prénoms des clients qui ont une commande:
SELECT nom, prenom FROM clients WHERE EXISTS (select * from commandes)
Voilà le résultat:
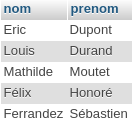
Heu…attendez voir, je fais quoi parmi ces résultats, je n’ai pas passé commande ! Que dit en réalité notre requête ? « Donne-moi le nom et prénom des clients tant qu’il EXISTE des commandes ». Il existe 5 commandes, j’ai donc 5 clients. Et oui, attention car à ce stade, nous n’avons absolument pas demandé de corrélation entre les résultats. Faisons-le et notez au passage que nous utilisons TRUE en lieu et place du joker « * » dans la sous-requête:
SELECT nom, prenom FROM clients c WHERE EXISTS (SELECT TRUE FROM commandes co WHERE c.id = co.client_id)
Voilà qui est nettement mieux, vous en conviendrez !
Alors, vous allez me dire, « Quel est l’intérêt d’utiliser EXISTS, nous sommes en train de faire ni plus ni moins qu’une jointure interne » et vous aurez raison. D’ailleurs, certaines personnes qui ont grand besoin d’une mise à jour en SQL s’en servent comme « jointure du pauvre ». La grosse différence, c’est que vous ne pouvez pas projeter des attributs potentiellement contenus dans la sous-requête, ce qui peut être fait avec un JOIN, interne ou externe. Ici nous ne pouvons projeter que nom et prenom, qui sont des attributs de la table clients. Pensez aussi à l’utilisation des index (utiliser EXPLAIN !)
To EXIST or not to EXIST?
Evidemment, EXISTS a aussi son contraire – comme NULL – c’est NOT EXISTS.
Reprenons la dernière requête (notez que TRUE est devenu 1)
SELECT nom, prenom FROM clients c WHERE NOT EXISTS (SELECT 1 FROM commandes co WHERE c.id = co.client_id)
Et hop ! Me voilà apparaissant dans les résultats !
![]()
Le prédicat EXISTS sur un UPDATE
Si je souhaite mettre le montant des commandes pour lesquelles il n’existe pas de client à 1, je ferai:
UPDATE commandes AS co
SET montant = 1
WHERE NOT EXISTS (SELECT * FROM clients c WHERE c.id = co.client_id)
C’est un peu moins délicat à écrire qu’un UPDATE avec une jointure.
Le prédicat EXISTS sur un DELETE
Ce n’est guère plus difficile, notez seulement que DELETE n’accepte pas nativement l’alias (AS), il faut donc mettre commandes en toutes lettres.
DELETE FROM commandes
WHERE NOT EXISTS (SELECT * FROM clients c WHERE c.id = commandes.client_id)
Autre exemple
Altérons notre relation commandes pour en faire celle qui suit:
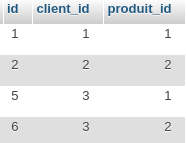
Et rajoutons une relation produits elle aussi tout à fait basique:
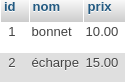
Maintenant supposons que nous souhaitions trouver le nom des produits de toute commande contenant une écharpe et qui ne sont pas une écharpe justement:
SELECT p.nom FROM commandes AS co
INNER JOIN produits p ON (p.id = co.produit_id)
WHERE produit_id != 2
AND EXISTS (select * from commandes AS co2 WHERE co.client_id = co2.client_id AND co2.produit_id = 2)
Nous cherchons les commandes qui contiennent le produit 2 dans la sous-requête et nous projetons ceux dont l’id n’est pas 2.