Voici la dernière partie de mon billet concernant les migrations Doctrine et le bundle associé.
Les relations des entités Doctrine
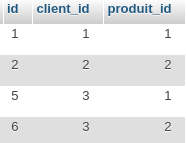
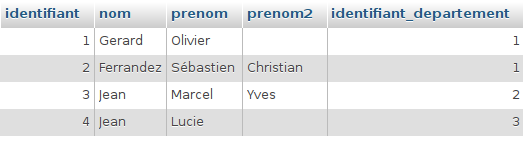
Nos élèves ont une relation avec leur filière. Nous en avons parlé au tout début lorsque nous définissions les cardinalités :
- un élève a une seule filière
- une filière a 0 ou plusieurs élèves
Il va nous falloir définir ceci au niveau de nos entités Doctrine. Nous allons donc « tirer un fil » entre nos entités Eleve et Filiere. Doctrine a des moyens de mettre ça en place et nous allons voir comment ceci se matérialise avec les annotations, que nous avons choisi de privilégier lorsque nous avons généré nos entités.
Entre Eleve et Filiere, il y a une relation de un à plusieurs (one to many en anglais). Nous la voulons bi-directionnelle dans le sens où nous souhaitons pouvoir à partir d’un élève récupérer sa filière et, à partir d’une filière, récupérer ses élèves. Dans l’entité Eleve, nous sommes du côté plusieurs de la relation (car plusieurs élèves correspondent à une filière). Voici comment nous allons nous servir des annotations Doctrine :
/**
* @ORM\ManyToOne(targetEntity="Filiere", inversedBy="eleves")
* @ORM\JoinColumn(name="filiere_id", referencedColumnName="id", nullable=false)
**/
private $filiere;
Nous définissons une variable d’instance privée filiere qui va aider Doctrine à stocker la filière d’un élève (il n’y en a qu’une possible, souvenez-vous). La cible de la relation que nous sommes en train de décrire dans l’entité Eleve est l’entité Filiere, c’est ce que nous dit targetEntity. Le inversedBy qui suit signifie que de l’autre côté de la relation (dans l’entité Filiere) nous trouverons l’attribut chargé de gérer cette relation sous le nom d’eleves (notez bien le pluriel car de l’autre côté de la relation nous aurons plusieurs élèves pour notre filière). JoinColumn décrit la manière physique dont cette relation va exister. En lisant, vous devinez que dans notre table nous allons avoir un champ rajouté suite à l’écriture de cette relation qui va identifier une filière pour un élève, que ce champ s’appellera filiere_id et qu’il référencera une colonne appelée id…Vous voyez déjà venir gros comme une maison la contrainte d’intégrité référentielle. Le nullable=false signifie qu’il faut obligatoirement une filière à un élève ; là aussi vous devez imaginer que cette clause entraînera la présence d’un NOT NULL dans le schéma relationnel.
Du côté de l’entité Filiere, nous avons l’annotation Doctrine suivante pour la variable d’instance eleves dont nous avons déjà parlé :
/**
* @ORM\OneToMany(targetEntity="Eleve", mappedBy="filiere")
**/
private $eleves;
public function __construct()
{
$this->eleves = new ArrayCollection;
}
Nous prenons la relation dans l’autre sens – « un vers plusieurs » – parce qu’une filière a plusieurs élèves. Voilà pourquoi cette fois c’est one to many en lieu et place du many to one qu’on trouvait dans Eleve. La cible, c’est bien Eleve et l’attribut qui va servir c’est bien filiere (private $filiere). Dans Eleve nous avions inversedBy, dans Filiere nous avons mappedBy. Doctrine détermine le côté « possesseur » de la relation par inversedBy et l’autre côté (« inverseur ») par mappedBy.
Comme nous avons potentiellement plusieurs élèves pour une filière, nous allons avoir à gérer plusieurs objets. Pour ce faire, Doctrine nous propose son type ArrayCollection, que vous allez pouvoir utiliser en faisant :
use Doctrine\Common\Collections\ArrayCollection;
Notre variable d’instance privée eleves sera de ce type et nous l’initialiserons dans le constructeur de notre classe.
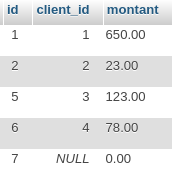
Nous avons construit notre première relation au niveau objet ! L’heure est venue de mettre notre schéma de bases de données à jour avec tout cela ! Allons-y !
app/console doctrine:migrations:diff
Ouvrons le fichier ainsi généré pour vérifier que notre relation est bien en place :
$this->addSql("ALTER TABLE eleve ADD filiere_id INT NOT NULL");
$this->addSql("ALTER TABLE eleve ADD CONSTRAINT FK_ECA105F7180AA129 FOREIGN KEY (filiere_id) REFERENCES filiere (id)");
$this->addSql("CREATE INDEX IDX_ECA105F7180AA129 ON eleve (filiere_id)");
Ce que nous envisagions est effectivement arrivé, nous avons bel et bien une contrainte d’intégrité référentielle posée entre la table eleve et la table filiere !
Lançons maintenant la migration :
app/console doctrine:migrations:migrate
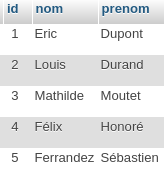
Notre table eleve a bien un champ en plus : filiere_id !
sebastien.ferrandez@sebastien:~/migrations$ mysql -u root -p -e 'use exercice; desc eleve'
Enter password:
+------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| nom | varchar(40) | NO | | NULL | |
| prenom | varchar(40) | NO | | NULL | |
| age | int(11) | NO | | NULL | |
| filiere_id | int(11) | NO | MUL | NULL | |
+------------+-------------+------+-----+---------+----------------+
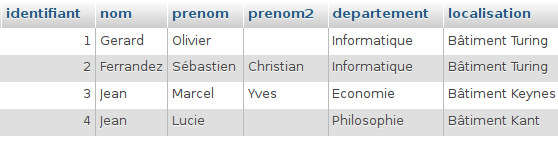
Occupons-nous ensuite des cours: un cours a des relations avec salle, enseignant et filière, en fait cours est au centre de tout…Quelles sont-elles exactement ? Reprenons ce que nous avions établi :
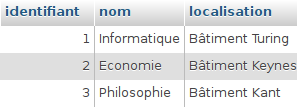
- une filière est composée d’un ou plusieurs cours
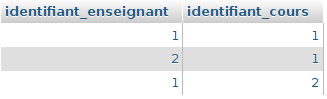
- un cours n’a qu’un seul et unique enseignant mais un enseignant a un ou plusieurs cours
- un cours se tient dans une seule salle à un moment donné et une salle peut abriter plusieurs cours. On peut très bien créer un cours sans salle car il arrive qu’on ne puisse décider de suite dans quelle salle il se tiendra. Elle sera rajoutée plus tard.
Les relations nous apparaissent évidentes. Un lien de type « un à plusieurs » existe entre cours et enseignant (« un à plusieurs » dans le sens enseignant → cours et « plusieurs à un » dans le sens inverse). Il en va de même pour les salles ou les filières. La seule différence réside en le fait qu’un cours a forcément un enseignant ou une filière alors qu’il n’a pas forcément de salle (on peut le créer sans salle pour lui en affecter une quand on a consulté le planning des salles et qu’on en a trouvé une de disponible). Nous allons donc nous retrouver à ajouter des annotations de type ManyToOne dans notre entité Cours.
/**
* @ORM\ManyToOne(targetEntity="Filiere", inversedBy="cours")
* @ORM\JoinColumn(name="filiere_id", referencedColumnName="id", nullable=false)
**/
private $filiere;
/**
* @ORM\ManyToOne(targetEntity="Salle", inversedBy="cours")
* @ORM\JoinColumn(name="salle_id", referencedColumnName="id")
**/
private $salle;
/**
* @ORM\ManyToOne(targetEntity="Enseignant", inversedBy="cours")
* @ORM\JoinColumn(name="enseignant_id", referencedColumnName="id", nullable=false)
**/
private $enseignant;
Vous noterez que salle est le seul endroit où nullable est à sa valeur par défaut, c’est à dire true et qu’il sera donc possible d’enregistrer un cours sans salle. Dans la mesure où nous avons pour un cours soit 0 (pour une salle) soit un (enseignant, filière) inutile ici d’utiliser les ArrayCollection comme c’était le cas pour matérialiser la relation filière/élève.
Dans chacune de ces entités cibles nous auront une variable d’instance nommée cours, c’est aussi ce que nous disent ces annotations.
Dans l’entité Salle :
/**
* @ORM\OneToMany(targetEntity="Cours", mappedBy="salle")
**/
private $cours;
public function __construct()
{
$this->cours = new ArrayCollection;
}
Ici par contre une salle est susceptible d’accueillir plusieurs cours (NFA057 le jeudi soir, NFA053 le mardi), la notion de collection a ici du sens. Idem pour les enseignants :
/**
* @ORM\OneToMany(targetEntity="Cours", mappedBy="enseignant")
**/
private $cours;
public function __construct()
{
$this->cours = new ArrayCollection;
}
Ou encore Filiere :
/**
* @ORM\OneToMany(targetEntity="Cours", mappedBy="filiere")
**/
private $cours;
Vous avez remarqué que le champ mappedBy de l’annotation pointe vers la variable d’instance correspondante dans l’entité Cours. Dans le cas de Filiere, l’entité avait déjà une instanciation de la classe ArrayCollection dans son constructeur, nous devons en rajouter une autre pour les cours, comme fait dans les autres entités, plus haut, ce qui donnera :
public function __construct()
{
$this->cours = new ArrayCollection;
$this->eleves = new ArrayCollection;
}
Une fois que nous avons mis nos relations dans nos 4 entités, il nous reste à exécuter une migration !
app/console doctrine:migrations:diff
app/console doctrine:migrations:migrate
feront apparaître les contraintes d’intégrité référentielle entre la table cours et enseignant, salle et filiere.
Maintenant que nous avons établi notre architecture objet avec nos entités, regardons avec MySQL Workbench à quoi ressemble notre schéma et surtout s’il satisfait à toutes les contraintes que nous avons énoncées au début du présent document :
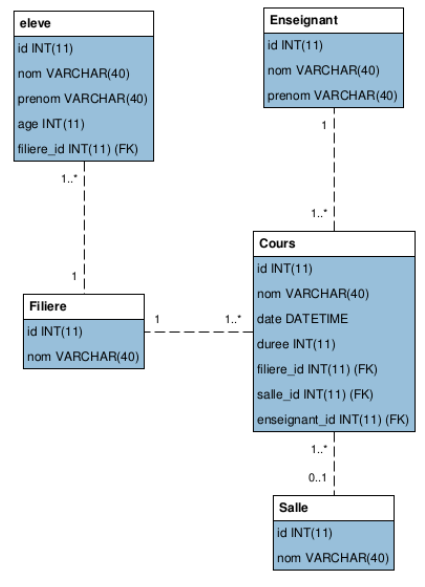
En naviguant à travers les relations, nous sommes sûrs que nous avons effectué du bon travail car elles correspondent en tous points à ce que nous souhaitions.
Au sujet des types de données utilisés par Doctrine, nous voyons qu’ils ne correspondent pas forcément à ce que nous recherchons en terme de plage de valeurs (des INTEGER pour gérer des âges – pas signés qui plus est -, des DATETIME alors que des TIMESTAMP, deux fois moins gourmands en espace disque, suffiraient). Il y a beaucoup à redire de ce côté là sur ce schéma mais sachez qu’il est toujours possible de forcer Doctrine à utiliser des types choisis par nos soins avant de passer une migration ! Il suffit d’en faire état dans les annotations de nos entités. Attention cependant, changer le type des données choisies par Doctrine peut faire que les changements d’état de votre schéma (de la colonne modifiée, pour être plus exact) ne sont pas pris en compte comme ils devraient l’être par Doctrine, qui ne retrouve plus ses types « natifs », puisque vous les avez modifiés.