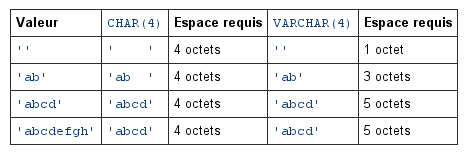
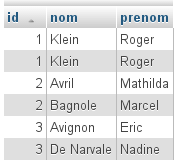
L’heure est venue de nous pencher sur la notion de clé étrangère dans une table. Les clés étrangères servent à établir des contraintes dites d’ « intégrité référentielle ».

Qu’est-ce qu’une clé étrangère ?
C’est un champ (ou une colonne, ou un attribut, ou une propriété) d’une table. Jusque là, voilà qui est plutôt rassurant !
Qu’est-ce l’intégrité référentielle ?
Dans cette expression, nous avons la notion centrale de « référence ». Il est en effet question d’un champ qui fait référence à un autre. Qu’est-ce que cela signifie, dans les faits ? Et bien simplement que, si A est un champ qui référence B, alors A aura pour valeurs admissibles un sous-ensemble des valeurs de B.
Plus concrètement, si votre champ B, référencé par A, a pour valeurs entières 1,2 et 3, alors A ne pourra avoir lui aussi que ces valeurs et pas 4 ou 0 !
Les clés étrangères dans MySQL
En SQL, quelque soit le SGBDR cible, la notion de clé étrangère s’applique à l’aide du mot clé FOREIGN KEY. Comme vous vous apprêtez à modifier la structure de la table pour lui imposer cette contrainte, vous devrez utiliser ALTER TABLE.
Nous allons voir la syntaxe en détail dans l’exemple à venir.
Un exemple, tout de suite !
Soit une table qui recense les joueurs d’un sport quelconque (qui se joue à deux):
create table joueur ( id smallint unsigned not null primary key, nom varchar(20), prenom varchar(20));
La table joueur possède un champ qui est son identifiant primaire : c’est id ! Ce champ là possède un index parce que je l’ai explicitement déclaré comme clé primaire de ma table (primary key). Voilà pour ma table joueur, qui est somme toute très simple.
Nous allons maintenant créer une table qui va servir à opposer un joueur à un autre :
create table matches ( id smallint unsigned not null primary key, id_joueur1 smallint unsigned not null, id_joueur2 smallint unsigned not null, duree tinyint unsigned not null);
Cette table là possède elle aussi un identifiant (une clé primaire): en plus de cet identifiant, elle possède deux champs qui vont correspondre à des identifiants de joueurs, donc à des valeurs du champ id présentes dans notre table joueur ! Dans l’état rudimentaire de cette table il est tout à fait possible de rentrer des joueurs, mais comment forcer l’utilisateur de nos données à ne rentrer que des identifiants de joueurs qui existent ? C’est là que la notion de clé étrangère entre en jeu !
Nous allons faire en sorte que les valeurs admissibles pour les champs id_joueur1 et id_joueur2 de la table matches soient uniquement celles présentes dans le champ id de la table joueur, en clair : interdit de faire s’affronter des joueurs qui n’existent pas !
Il va nous falloir modifier la structure de la table matches, il y a donc de l’ALTER dans l’air ! Notez qu’il va falloir créer un index sur le champ référençant (celui qui va servir à référencer l’autre, qui est le référencé) : cet index est INDISPENSABLE car il évite les full table scans et accélère donc la vérification des contraintes d’intégrité référentielle !
ALTER TABLE matches ADD INDEX (id_joueur1); ALTER TABLE matches ADD FOREIGN KEY (id_joueur1) REFERENCES joueur (id);
La voilà enfin notre référence ! Nous disons en substance « crée moi un lien entre le champ id de joueur et le champ id_joueur1 de matches » ! Dorénavant, toute tentative d’insérer un identifiant de joueur qui n’existe pas se soldera par un échec ! Faisons le de suite :
mysql> insert into matches (id_joueur1) values (1); ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`test`.`matches`, CONSTRAINT `matches_ibfk_1` FOREIGN KEY (`id_joueur1`) REFERENCES `joueur` (`id`))
Il n’y a pas de joueur dans la table qui leur est réservée, donc toute tentative de rentrer un numéro de joueur dans id_joueur1 sera sanctionnée par ce message d’erreur !
Pour que la même contrainte pèse sur le champ id_joueur2, il faut effectuer exactement la même opération que précédemment, à avoir : la pose d’un index sur le champ ET la pose de la clé étrangère :
ALTER TABLE matches ADD INDEX (id_joueur2); ALTER TABLE matches ADD FOREIGN KEY (id_joueur) REFERENCES joueur (id);
Voilà que maintenant pèse sur notre table matches deux contraintes d’intégrité référentielle qui font qu’il n’est possible de faire s’affronter que des joueurs répertoriés dans notre table joueur !
La fin d’une idée reçue
Je me suis aperçu que beaucoup de gens étaient encore persuadés qu’une contrainte de clé étrangère ne pouvait s’appliquer qu’entre un champ référençant et un champ référéncé obligatoirement clé primaire de sa table. C’est absolument faux et ce même si en pratique on s’en sert le plus souvent comme ça ! Pour qu’un champ puisse en référencer un autre, il suffit que tous les deux soient indexés et rien de plus. Comme la clé primaire est par définition un index, c’est elle qui rend cette référence possible mais autrement, vous pouvez tout à fait dans T1(A,B) faire que B référence D de T2(C,D) qui n’est pas le moins du monde la clé primaire de T2 ! (les C.P sont en gras)
A retenir
- Pour poser une clé étrangère sur A qui référence B, il faut que A et B soient rigoureusement du même type ! Attention quand vous utilisez des types numériques, il faut que les signes (SIGNED/UNSIGNED) soient identiques !
- Seul le moteur InnoDB autorise l’utilisation de ce mécanisme !
- On remplit d’abord les tables référencées avant de remplir les référençantes !
- On vide les tables référençantes avant de vider les référencées !
- Si vous souhaitez contourner momentanément la vérification des contraintes d’intégrité, pour charger des données en masse par exemple, utilisez SET FOREIGN_KEY_CHECKS = 0;